





I. 서론
교육평가는 학습자의 학업 성취를 진단하고 교육목표 달성 여부를 규명하는 필수적 학술 활동으로, 교수‧학습 과정의 개선뿐 아니라 교육 정책 수립의 근거를 제공한다(박도순, 2009; 성태제, 2014). 특히 고등학교 국어과 독서 영역 평가는 단순한 정보 이해를 넘어 비판적‧창의적 사고, 정보 통합 등 고차원적 사고 역량을 심층적으로 측정해야 한다(권태현, 이정찬, 김승현, 2017). 이러한 복합적 평가 요구는 사실적 이해, 추론, 비판, 창의 사고를 위계적으로 진단할 수 있는 정교한 문항 설계를 전제하며, 출제자의 고도화된 전문성을 필수 조건으로 설정한다(김혜정, 2008; 정혜승, 2008).
그러나 현재 단위학교 문항 개발은 교사의 직관과 경험에 크게 의존하고 있으며, 수작업 중심의 개발 체계는 평가 도구의 일관성과 타당성 확보에 구조적 한계를 노출한다(Gierl & Haladyna, 2013). 실제로 남민우 외(2022)는 고등학교 국어과 지필 평가 문항을 분석한 결과, 성취기준과 문항 간의 불일치, 선택지 논리 오류, 사고 수준 불일치 등의 문제가 광범위하게 확인되었으며, 이는 문항 개발 역량의 차이가 문항의 질적 불균형으로 이어질 수 있음을 시사한다. 정혜승(2008) 역시 이러한 문제를 지적하며 교사의 평가 역량의 격차가 문항의 타당성과 신뢰도에 직접적인 영향을 미친다고 보고하였다. 이러한 문제는 평가 주체의 전문성 차이를 반영하며, 문항의 질적 불균형을 초래할 수 있는 실질적 요인으로 작용한다.
이러한 문제의식 속에서 자동 문항 생성(Automatic Item Generation, AIG)에 대한 관심이 지속적으로 확대되고 있다. AIG는 초기에 템플릿 기반의 정형적 접근에서 출발하여, 이후 대규모 언어 모델(Large Language Models, LLMs)과 자연어처리(Natural Language Processing, NLP)의 발전에 힘입어 생성형 인공지능(Generative AI, GAI)을 활용한 방식으로 진화하고 있다(Gierl, Hollis & Tanygin, 2021; Kasneci et al., 2023). GAI 기반 AIG는 생산성과 다양성을 극대화할 수 있다는 점에서 주목받고 있으나, 교육적 타당성, 논리적 정합성, 교육과정과의 연계성 확보에 한계가 있다는 비판이 지속적으로 제기되어 왔다. Cong-Lem, Soyoof & Tsering(2025)은 ChatGPT와 같은 대규모 언어 모델이 정확성과 신뢰성, 비판적 사고와 문제 해결 능력, 기술적 제약 등에서 다면적인 한계를 지니고 있어 교육평가 영역에서는 신중한 접근이 필요하다고 지적하였다.
이러한 한계를 보완하기 위한 대안으로 Human-in-the-Loop(HITL) 접근이 대두되고 있다. HITL은 AI 시스템의 의사결정 과정에 인간 전문가의 판단과 개입을 통합하여 결과물의 품질을 향상시키는 방법론으로, 교육 분야에서는 AI가 생성한 문항을 교사가 검토하고 개선하는 협업 구조를 의미한다(Memarian & Doleck, 2024; U.S. Department of Education, 2023). 실제 최근 생성형 AI를 활용한 자동 문항 생성의 품질 검증을 위해 심리측정학적으로 분석하고 타당화를 실시하는 연구가 확산하는 추세이다. 이러한 국제적 연구 동향과 맥을 같이하여, 국내에서도 AIG 과정에서 교사와 AI의 협업 필요성을 강조하는 연구들이 나타나고 있다. 이하늘, 이용상(2024)은 GPT-4.0을 활용한 한국어 읽기 문항 자동 생성에서 교사 피드백과 조정이 포함된 협업 구조의 필요성을 제안하였으며, 박고운, 최숙기(2025)는 사고 연쇄(Chain-of-Thought, CoT) 프롬프팅 기반 국어과 AIG 모델 연구에서 교사의 피드백이 반복적으로 개입하는 HITL 구조가 필요하다고 제언하였다.
그러나 현존하는 HITL 기반 AIG 연구는 대부분 개념적 모델 제시나 전문가의 직관적 평가에 국한되어 있으며, 생성 문항을 실제 교육 현장에 투입하고 학습자 응답 데이터를 바탕으로 심리측정학적 특성을 정량적으로 검증한 실증 연구는 여전히 제한적이다(Bejar et al., 2003; Memarian & Doleck, 2024). Song, Du & Zheng(2025)의 체계적 문헌 고찰에 따르면, 최근 15년간 수행된 AIG 관련 연구 중 문항 난이도 및 변별도를 실측 데이터를 통해 평가한 사례는 매우 드문 것으로 나타났다. Young et al.(2025)은 ChatGPT-4가 생성한 다지선다형 문항을 문항반응이론(Item Response Theory, IRT)과 전문가 평가를 통해 분석하여, 생성된 문항들이 논리적으로 타당하고 학습 목표에 부합하나 전반적으로 난이도가 낮고 변별력이 높아 총괄 평가보다는 형성 평가에 적합하다고 보고하였다. 이러한 선행연구의 흐름을 고려할 때, 국내에서도 AIG 결과에 대한 객관적이고 정량적인 심리측정 분석의 필요성이 강하게 제기된다.
본 연구에서는 이러한 선행연구의 흐름을 고려하여 생성형 AI와 교사 전문가의 협업을 통해 문항을 점진적으로 고도화하는 반복적이고 상호보완적인 협업 과정을 Generative AI-Human-in-the-Loop(이하 GAI-HITL)로 정의하였다. 이를 기반으로 한 AIG 프로토콜에 의해 생성된 문항 결과를 학습자 응답 데이터를 기반으로 문항의 타당성을 실증적으로 분석하여 관련 이론을 검증하고자 하는 것을 목적으로 한다.
이에 본 연구는 GAI-HITL 방식을 기반으로 한 고등학교 국어과 독서 AIG 결과의 심리측정학적 특성을 난이도 및 변별도 측면에서 체계적으로 분석함으로써, 해당 방식의 타당성과 실용 가능성을 실증적으로 평가하고자 한다. 이를 위해 본 연구는 다음과 같은 세 가지 연구 문제를 설정하였다.
첫째, GAI-HITL 방식으로 개발된 독서 문항의 난이도는 교사 예측, CTT, IRT 분석에서 어떤 특성과 상관성을 보이는가?
둘째, GAI-HITL 방식으로 개발된 독서 문항의 변별도는 CTT 및 IRT 기준에서 어떤 특성과 관계를 나타내는가?
셋째, 난이도와 변별도에 대한 분석 결과를 종합할 때, GAI-HITL 방식의 문항 개발이 평가 도구로서 갖는 심리측정학적 품질은 어떠한가?
본 연구는 다음과 같은 학술적 및 실천적 기여를 지닌다. 첫째, 이론적 기여 측면에서 본 연구는 GAI-HITL을 통해 생성된 문항의 난이도와 변별도를 정량적으로 분석하고, 교사 예측과 실제 반응 간의 상관성을 검증함으로써 실증적 근거를 제공한다(Leslie & Gierl, 2023; Song, Du & Zheng, 2025). 둘째, 실천적 기여 측면에서 본 연구는 GAI-HITL 기반 문항의 심리측정학적 품질을 검증함으로써, 교사들이 AI 생성 문항을 신뢰하고 교육 현장에 적용할 수 있는 실용적 근거를 제공한다(U.S. Department of Education, 2023).
II. 이론적 배경
2015 개정 국어과 교육과정은 독서 역량을 학습자의 인지적 성장과 고차 사고 능력을 심화하는 핵심 축으로 설정하고 있으며, 독서 교육의 목표를 사실적 이해에서 시작하여 추론, 비판, 창의적 사고로 이어지는 위계적 구조 속에 체계화하였다(교육부, 2015). 이러한 위계는 단순한 정보 해독을 넘어, 텍스트의 구조와 논리를 분석하고, 사회문화적 맥락 속에서 의미를 재구성하며, 타당성과 관점을 비판적으로 평가하는 고차 사고 능력으로 연결된다(김혜정, 2011; 정혜승, 2008). 독서 교육은 따라서 학습자의 능동적 의미 구성과 인지적 전이를 이끄는 복합적 사고 활동으로 자리매김하며, 이는 평가 장면에서도 구조적 정합성과 타당성을 갖춘 문항 설계를 통해 구현되어야 한다(정민주 외, 2022). 특히 교육과정은 독서 능력을 단순한 기술적 독해가 아니라 지식의 구성과 문제 해결, 창의적 발상까지 아우르는 복합적 사고 능력으로 간주하며, 이에 따라 독서 평가는 단일 정답을 도출하기 어려운 복합 사고 과정의 구조적 반영을 요한다(남민우 외, 2022).
이러한 교육과정의 목표는 대학수학능력시험 국어 영역의 독서 문항 구성과 밀접하게 연결되어야 한다. 정혜승(2008)은 독서 평가 문항이 텍스트의 구조적 특성과 독자의 인지적 처리 과정을 종합적으로 고려해야 하며, 특히 정보 간의 관계 분석과 추론적 사고를 측정할 수 있는 설계가 필요하다고 강조하였다. 김혜정(2011)은 독서 능력 평가에서 사실적 이해, 추론적 이해, 비판적 이해의 위계적 구조가 문항 설계에 체계적으로 반영되어야 하며, 각 수준별 사고 과정의 특성을 고려한 평가 도구 개발이 중요하다고 지적하였다. 정민주 외(2022)는 독서 평가가 단순한 정보 확인을 넘어서 텍스트 내 정보의 통합과 재구성, 비판적 판단을 요구하는 복합적 사고 과정을 측정해야 한다고 보았다. 이러한 관점에서 독서 문항은 학습자의 인지적 처리 과정과 사고의 깊이를 구조적으로 평가할 수 있는 설계 원리를 필요로 한다.
그러나 이러한 문항 설계는 고도의 평가 설계 역량을 요구하며, 실제 문항 개발 현장에서는 다양한 난제가 제기된다. 특히 독서 능력의 위계적 구조를 평가 문항에 충실히 반영하려 할 때, 각 사고 수준을 명확히 구분하면서도 하나의 문항 내에서 사고의 흐름을 논리적으로 구성하는 데 현실적 제약이 발생한다(남민우 외, 2022; 정민주 외, 2022). 문항이 평가하려는 사고 수준이 불명확하거나 선택지가 오답 유도 요인으로 작용하지 못할 경우, 문항의 변별력이 약화되고 평가의 타당성도 저해될 수 있다(김혜정, 2008). 이러한 상황은 특히 선다형 문항 형식의 구조적 한계와도 연결되며, 복합적 사고를 요구하는 평가 내용과 단일 선택지 형식 간의 불균형이 근본적인 긴장을 형성한다.
이러한 문제는 수능과 같은 국가 수준 평가뿐 아니라 학교 현장의 지필 평가에서도 유사하게 나타난다. 장성민(2024)은 고등학교 국어과 교사들이 독서 영역의 평가 문항을 출제하는 과정에서 위계적 사고에 기반한 문항 설계에 어려움을 겪고 있으며, 이는 문항 개발자의 평가 문식성과 독서 이론에 대한 이해 부족, 검토 체제의 부재, 그리고 실무적 제약 등과 복합적으로 연결된다고 지적하였다. 특히 교사들이 경험적으로 문항을 구성할 경우, 고차 사고를 측정하기 위한 평가 목적이 구체화 되지 않거나, 평가 도구로서의 논리적 완결성이 부족해질 가능성이 크다. 정혜승(2008) 또한 교사의 독해력, 글 구조 분석 능력, 질문 설계 능력의 격차가 문항의 타당성과 신뢰도에 직접적인 영향을 미친다고 보고하였다. 이는 평가 주체인 교사의 전문성 신장을 요구하는 것이며, 문항의 질적 불균형을 초래할 수 있다.
결국 2015 개정 교육과정이 지향하는 독서 능력의 위계적 발달과 고차 사고 중심의 평가 설계는 선다형 문항 체제에서도 충분히 반영되어야 하며, 이를 위해서는 문항의 사고 수준 설계, 지문과 문항 간 정합성, 선택지 구성의 정교함 등 다양한 측면에서 질적 기준이 요구된다. 이러한 기준은 단지 평가도구로써의 기능을 넘어서, 학습자의 사고 경로를 추적 가능하게 하고, 교수·학습 과정에서의 환류 자료로 기능하기 위해 필수적이다. 본 연구는 이러한 관점에서 수능에서 요구하는 수준의 독서 능력을 평가할 수 있는 선다형 문항을 생성형 인공지능 기반(AIG)으로 개발하고, 그 타당성을 실증적으로 분석하고자 한다. 특히 생성형 AI의 도입은 기존 문항 개발의 전문성·효율성 문제를 일정 부분 보완할 수 있는 기술적 가능성을 제시하며, 이는 평가의 질적 향상을 위한 새로운 전환점으로 기능할 수 있다.
자동 문항 생성(AIG)은 평가 설계 및 개발 과정을 디지털화하여 효율성과 일관성을 높이는 평가 공학(Assessment Engineering) 기반의 접근법이다(오규설, 2022). 초기 AIG는 미리 정의된 문항의 구조적 틀에 특정 변수 값을 대입하는 ‘템플릿 기반’ 방식으로 이루어졌다. 이 방식은 문항의 형식이 고정된 수학, 과학 등에서는 유용했으나, 다양한 맥락과 의미를 다루어야 하는 언어 평가 문항을 생성하는 데에는 명백한 한계를 가졌다.
이러한 한계는 GPT와 같은 대규모 언어 모델(LLM)을 활용한 AIG 연구를 통해 새로운 국면을 맞이하고 있다. 이 접근 방식은 주어진 텍스트를 바탕으로 지문은 물론이고 발문, 정답 및 선택지를 통합적으로 생성할 수 있어 문항 구성의 전 과정 및 핵심 요소를 도출하는데 AIG 기법을 적극적으로 활용하고 있다. von Davier(2018)는 신경망 기반의 AIG 과정을 ‘사전 준비-문항 생성-검토 및 수정-문항 최적화’의 4단계로 체계화하여, 이후 LLM 기반 AIG 연구의 이론적 토대를 마련하였다.
LLM을 활용한 문항 생성 연구는 모델이 발전함에 따라 그 품질 또한 향상되는 추세를 보인다. AI가 생성한 문항은 전문가 검토를 거칠 경우 교사의 업무 부담을 획기적으로 줄일 수 있는 초벌 안으로서 잠재력을 보여준다(Biancini, Ferrato & Limongelli, 2024; 임상묵 외, 2024). 그러나 AI가 생성한 문항에는 내용적 오류나 논리적 비약이 포함될 수 있으며, 특히 정답이 모호하거나 오답 선택지가 비현실적인 경우가 있어 최종 사용을 위해서는 전문가의 검토가 필수적이라는 점이 국내외 연구에서 공통적으로 지적된다(Grévisse, 2023; 박고운, 최숙기, 2025; 임상묵 외, 2024; 이하늘, 이용상, 2024).
해외에서는 생성된 문항의 교육적 품질을 체계적으로 분석하려는 연구가 활발히 진행되고 있다. 특히, 생성 문항을 블룸의 분류법(Bloom’s Taxonomy)과 같은 인지적 위계에 맞춰 정렬하고 그 품질을 평가하는 연구가 주목받고 있다. 한 연구에서는 GPT-3.5가 블룸의 분류법 수준에 따라 문항을 생성하도록 지시했으나, 인간 전문가가 ‘고품질’이라고 판단한 문항은 57개 중 12개에 불과했다. 특히, 블룸의 분류법에서 ‘평가’나 ‘종합’과 같이 상위 수준으로 갈수록 GPT-3.5가 고품질 문항을 생성하는 데 더 큰 어려움을 겪는 경향이 관찰되었다. 이러한 연구는 AIG 기술이 기초적인 지식 확인에는 유용하지만, 고차원적인 사고를 측정하는 문항을 안정적으로 생성하기 위해서는 개선이 필요함을 시사한다(Hwang et al., 2024).
이러한 한계를 극복하기 위해 최근에는 생성 문항의 논리적 완결성을 높이는 사고 연쇄(CoT) 프롬프팅과 인간-AI 협력 모델이 주목받고 있다. CoT 프롬프트를 적용하면 단순히 예시를 제공하는 방식보다 문항의 완성도가 높아지지만, 여전히 고차원적인 비판적 사고를 요구하는 문항 생성에는 한계를 보인다(박고운, 최숙기, 2025). 이와 함께 인간-인공지능 협력(HITL)은 생성–검증–재구성의 순환을 안정화하는 운영 원리로 자리매김하였다. 교육 분야 AI에 대한 체계적 문헌 고찰 연구는 인간 전문가의 개입이 목표 정렬, 책임성 확보, 그리고 맥락 적합성을 높이는 데 결정적인 역할을 함을 보여준다(Memarian & Doleck, 2024). 나아가 비판적 사고 평가 문항 생성을 목표로 한 STAIR-AIG 연구는, AI가 1차로 생성한 문항을 다단계 전문가 검토와 재생성 과정을 반복하는 모듈화된 루프를 통해 문항의 품질을 체계적으로 향상시킬 수 있음을 실증하였다(Kim et al., 2025).
요약하면, 최신 AIG 기술은 LLM의 발전을 통해 문항 생성의 자동화 수준을 빠르게 높여가고 있으나, 생성된 문항의 사고 수준을 정교화하고 교육과정과의 정합성을 확보하며 선택지의 타당성을 검증하는 등의 고차원적 판단은 여전히 인간 전문가의 개입이 필수적이다. 따라서 CoT 프롬프팅과 같은 고도화된 기술과 HITL 기반의 인간-AI 협업 모델을 결합하는 방식이 현실적인 대안으로 주목받고 있다(신동광, 2024). 이러한 연구들은 자동화 기술과 교사의 전문성을 융합하는 것이 미래 교육 평가의 질을 높이는 핵심 전략임을 보여준다.
대규모 언어 모델(LLM)의 성능이 발전함에 따라, 모델의 잠재력을 최대한 이끌어내기 위한 프롬프트 엔지니어링(Prompt Engineering)의 중요성이 부각되고 있다. 단순한 질의응답을 넘어 복잡한 과업을 수행하기 위해서는 모델의 추론 과정을 체계적으로 유도하고 제어하는 정교한 프롬프트 설계가 필수적이다. 특히 교육 평가 문항 생성과 같이 고도의 논리적 정확성과 교육적 타당성을 요구하는 분야에서는 최신 프롬프트 전략에 대한 이해가 중요하다.
최신 프롬프트 전략의 근간에는 인-컨텍스트 학습(In-Context Learning, ICL)이라는 LLM의 독특한 학습 방식이 자리 잡고 있다(Brown et al., 2020). ICL은 모델의 가중치를 직접 수정하는 파인튜닝(fine-tuning)과 달리, 프롬프트 내에 몇 가지 과업 예시(demonstrations)를 함께 제공하여 모델이 주어진 맥락(context) 안에서 과업의 패턴을 학습하고 해결하도록 유도하는 기법이다. 예를 들어, 프랑스 -> 파리, 일본 -> 도쿄, 한국 -> ? 와 같이 예시를 제시하면, 모델은 ‘국가-수도’라는 패턴을 맥락 안에서 학습하여 ‘서울’이라는 답을 도출한다. 이처럼 예시를 제공하는 방식을 ‘퓨샷(Few-Shot) 프롬프팅’이라 하며, 본 연구에서 AI에게 기출 문항 예시를 제공한 것 역시 이 원리를 활용한 것이다.
ICL을 기반으로 한 획기적 전환은 사고 연쇄(CoT) 전략의 등장으로 이루어졌다. Wei et al.(2022)은 복잡한 추론 문제가 주어졌을 때, 최종 답변만 요구하는 대신 중간 추론 단계를 명시적으로 포함하도록 유도하면 LLM의 성능이 비약적으로 향상됨을 실증했다. 이 방식은 모델이 단계별로 논리적 사고를 수행하게 함으로써 문제 해결의 정확성과 일관성을 높였으며, 본 연구의 8단계 프로토콜 설계에 핵심적인 이론적 기반을 제공했다. CoT의 등장은 모델의 ‘생각’ 과정을 외부로 드러내어 통제하려는 후속 연구들로 이어졌다. Huang, Zhang & Liu(2022)는 여기서 더 나아가 LLM이 스스로의 추론 과정을 서술하는 ‘내적 독백(Inner Monologue)’ 기법을 제안했다. 이는 AI가 현재 사고하는 지점과 문제점을 스스로 밝히게 함으로써, 인간 전문가가 어느 지점에 개입하여 맥락을 재구성해야 할지를 명확히 알려주는 역할을 한다.
최근에는 한 단계 더 발전하여, AI가 자신의 초기 답변을 스스로 비판하고 수정하는 ‘자기 수정(Self-Correction)’ 또는 ‘자기 개선(Self-Refinement)’ 전략이 활발히 연구되고 있다(Madaan et al., 2023; Shinn et al., 2023). 이는 AI의 메타인지 능력을 활용하여 결과물의 질을 내부적으로 향상시키는 방식으로, 본 연구 프로토콜의 ‘6단계: 자기 점검 및 오류 탐지’ 과정에 직접적으로 반영되었다. 또한, 단일한 사고 경로를 넘어 여러 추론 경로를 탐색하고 최적의 답을 선택하는 ‘사고의 나무(Tree-of-Thoughts, ToT)’ 와 같은 더 발전된 프롬프팅 기법도 제안되며(Yao et al., 2023), 프롬프트 전략은 더욱 정교화되는 추세이다.
이러한 프롬프트 전략들은 복잡한 과업 수행 중 발생할 수 있는 맥락 상실(context loss)과 논리적 비일관성 문제를 보완하는 데 효과적이다(Maity, Deroy & Sarkar, 2024). 특히 고품질의 평가 문항을 생성하기 위해서는 결과물의 최종 검토뿐만 아니라 생성 과정 전반에 걸친 체계적인 품질 관리가 필수적이다. Shah(2024)가 제안한 ‘다단계 검증(multi-stage verification)’ 개념은 이러한 필요성을 충족하는 전략으로, AI가 생성한 결과물을 여러 단계에 걸쳐 체계적으로 검증함으로써 논리적 일관성과 타당성을 확보하고자 한다.
결론적으로, 본 연구의 GAI-HITL 프로토콜은 인-컨텍스트 학습(ICL)을 바탕으로 사고 연쇄(CoT)를 기본 골격으로 삼고, 내적 독백을 통해 AI의 사고 과정을 투명하게 드러내어 인간의 개입 지점을 확보하며, 자기 수정 개념을 활용해 AI의 자체적인 품질 관리 능력을 유도하는 최신 프롬프트 전략들을 종합적으로 반영한 결과물이다.
III. 연구 방법
본 연구는 GAI-HITL 기반 자동 문항 생성 프로토콜을 통해 개발된 평가 문항을 실제 교육 현장에 적용하고, 학습자의 반응 자료를 수집함으로써 문항의 심리측정학적 타당성과 실용성을 검증하고자 하였다. 문항 적용은 정규 수업의 자연스러운 맥락 내에서 이루어졌으며, 이를 통해 생성형 AI 기반 문항이 실제 학습자에게 유의미한 반응을 유도하고 문항으로서의 기능을 충실히 수행하는지를 실증적으로 확인하고자 하였다.
연구 참여자는 전라남도 소재 일반계 A고등학교 3학년 재학생 55명으로 구성되었으며, 이들은 모두 동일한 국어 교사의 <독서> 과목 정규 수업을 수강 중인 집단이었다. 평가 문항은 2025년 5월 1주차 정규 수업 시간에 일괄적으로 실시되었으며, 각 학생은 개별적으로 제공된 문항지에 응답하였다. 자료 수집 직후 응답지를 검토한 결과, 전 문항에 무응답하거나 전 문항에 정답만을 표시한 2명의 응답은 비정상적 반응 사례로 간주되어 최종 분석에서 제외되었다.
응답 자료는 각 문항별로 학습자가 선택한 선지와 정답 여부(정답: 1, 오답: 0)를 기준으로 코딩되었으며, 이후 문항별 정답률, 선지 선택 빈도, 학습자별 총점 분포 등 기초 통계량을 산출할 수 있는 형태로 전처리되었다. 사전 정제 과정에서는 결측 응답 확인, 이상 반응 제거, 정오 처리 일관성 검토 등이 포함되었으며, 이는 후속 통계 분석(고전검사이론 및 문항반응이론 기반)의 정확성과 해석 가능성을 확보하기 위한 필수 절차로 수행되었다.
본 연구에서는 고등학교 독서 교육에서 요구되는 평가 타당성을 확보하기 위해, 문항 생성을 위한 기준으로 『2015 개정 국어과 교육과정』의 독서 영역 성취기준을 적용하였다. 적용된 성취기준은 크게 두 영역으로 구분되며, 첫째, 독서의 방법 영역에서는 글에 드러난 정보를 바탕으로 중심 내용, 주제, 구조 등을 파악하는 사실적 이해(12독서02-01), 드러나지 않은 정보를 추론하는 능력(12독서02-02), 글의 관점이나 표현, 사회적 이념 등을 비판적으로 이해하는 능력(12독서02-03), 필자의 관점에 대한 대안 탐색 과 같은 창의적 읽기(12독서02-05)를 포함한다. 둘째, 독서의 분야 영역에서는 인문·예술(12독서03-01), 사회·문화(12독서03-02), 과학·기술(12독서03-03) 분야별 특성과 관련된 비판적 이해 능력을 요구하고 있다(<표 1> 참고).
이러한 성취기준을 바탕으로, 문항 생성을 위한 지문은『2026학년도 수능특강 국어영역 독서』(한국교육방송공사, 2025) 교재에서 선정하였다. 해당 교재는 고등학교 3학년 수업에서 실제로 활용되는 대표적인 연계 교재로, 교육부와 한국교육과정평가원의 감수를 받은 공신력 있는 자료이다. 본 연구에서는 2025년 3∼4월 중 실제 수업 시간에 다루어진 총 10편의 지문1)을 1차 후보군으로 설정한 뒤, 후보 지문에 대한 세 명의 교사 협의가 이루어졌다. 이때, 이 과정에 참여한 교사 3인의 평균 교육 경력은 10년이며, 고등학생을 대상으로 다년간 대학수학능력시험 대비 독서 교육 및 평가 문항 출제 경험을 보유하였기에 논의의 전문성을 확보하였다. 특히 문항 생성 프로토콜에 직접 참여한 교사 1인(이하 ‘개발 교사’)은 GAI-HITL 프로토콜에 대한 사전 이해를 바탕으로 AI와의 협업을 주도하였으며, 최종 문항 검토에 참여한 교사 2인(이하 ‘검토 교사’)은 동료 검토자로서 문항의 객관성과 교육적 적합성을 검증하는 역할을 수행하였다. 이들의 반복 협업을 통해 최종적으로 6편의 지문이 선정 되었고, 이때의 선정 기준은 ①교육과정 성취기준과의 정합성, ② 다양한 독해 기능과 수준별 문항 도출 가능성, ③평가 목적과 수업 맥락과의 부합성 등을 중심으로 설정하였다.
최종 선정된 지문은 기술, 사회, 인문 등 세 가지 분야에 고르게 분포하였으며, 각 지문은 학습자의 사고력을 촉진할 수 있는 주제를 담고 있다. 예를 들어, ‘관세의 기능과 종류’와 같은 사회 영역 지문은 비판적 사고를 유도할 수 있는 맥락을 포함하고 있으며, ‘지각에 대한 김창협의 주장’과 같은 인문 지문은 상반된 관점을 제시함으로써 고차 사고를 자극하는 데 적절하다. 각 지문에 대한 구체적인 제재 영역, 주제, 페이지, 문항 수는 <표 2>에 정리하였다. 이후 단계에서는 이러한 지문을 바탕으로 ChatGPT와 교사 협업을 통해 사고 유형별 문항이 생성되었다.
최종 선정된 6개 지문은 <표 2>와 같으며, 이후 문항 개발 및 검토 과정을 거쳐 각 지문별로 2∼4개의 문항이 최종 확정되었다.
본 연구는 고등학교 독서 교육과정의 성취기준에 부합하는 평가 문항을 자동으로 생성하고, 생성형 인공지능(ChatGPT-4o)과 현장 국어 교사의 구조적 협업을 통해 정교화함으로써 문항의 교육적 타당성과 심리측정학적 적절성을 동시에 확보하고자 하였다. 이를 위해 박고운, 최숙기(2025)가 제안한 CoT 프롬프트 설계 방식과 Huang, Zhang & Liu(2022)의 내적 독백(inner monologue) 기반 대형 언어 모델(LLM) 구성 원리를 이론적 배경으로 삼아, AI의 생성 과정을 외화하고 교사의 개입 가능성을 구조화한 GAI-HITL 기반 자동 문항 생성 프로토콜을 설계하였다.
이 프로토콜은 총 8단계로 구성되며, AI의 사고 흐름을 명시적으로 구조화하고 교사가 각 단계마다 실시간으로 협업하여 문항의 구성과 논리를 정교화할 수 있도록 설계되었다.
① 페르소나 설정 및 조건 제공: 개발 교사가 AI에게 ‘수능 국어 독서 문항 출제 전문가’와 같은 구체적인 역할을 부여하고, 5지 선다형 형식, 측정하려는 사고 유형(사실, 추론, 비판, 창의), 교육과정 성취 기준 등 문항 생성의 기본 조건을 명확히 설정한다. 이 단계에서 교사는 초기 출제 맥락이 평가 목적에 부합하는지 점검한다.
② 교육과정 분석 및 평가 요소 도출: AI는 제시된 성취기준을 분석하여 문항이 측정해야 할 교육 목표와 평가 요소를 구조화한다. 교사는 AI가 성취기준의 핵심을 정확하게 이해하고 반영했는지 검토하고 감독한다.
③ 지문 구조 분석 및 개념 정리: AI는 주어진 독서 지문을 읽고 핵심 개념, 논지 전개 방식, 문단 간의 관계 등 텍스트를 구조화하고 그 내용을 요약한다. 교사는 AI의 지문 해석에 논리적 오류나 왜곡이 없는지 검토한다.
④ 예시문항 풀이 및 근거 도출: 개발 교사는 AI에게 해당 지문과 관련된 기출 문항(예: EBS 수록 문항)을 제시하고, 그 풀이 과정과 정답 및 오답의 근거를 지문에서 찾아 설명하도록 요구한다. 이를 통해 교사는 AI가 실제 평가 문항의 출제 패턴과 사고의 흐름을 정확히 학습했는지 확인하고, 잘못된 추론 과정을 보일 경우 즉시 개입하여 수정한다.
⑤ 인지 영역별 문항 설계: 앞선 분석을 바탕으로 AI는 설정된 인지 영역(사실, 추론 등)의 목표에 맞춰 새로운 문항의 발문과 선택지를 구체적으로 설계한다. 교사는 이 단계에서 문항의 구성 논리가 타당한지, 의도한 인지 수준과 일치하는지를 집중적으로 검토한다.
⑥ 자기 점검 및 오류 탐지: AI는 스스로 생성한 문항 초안에 대해 논리적 비약, 발문과 선택지 간의 불일치, 매력적이지 않은 오답 등 잠재적 오류를 메타인지적으로 점검하고 그 결과를 보고한다. 이는 교사가 AI의 사고 과정을 파악하고 이후 정교한 피드백을 제공하는 중요한 기반이 된다.
⑦ 문항 초고 및 해설 작성: 자기 점검을 마친 AI는 발문, 정답, 오답 선택지, 그리고 상세한 해설을 포함한 완전한 형태의 문항 초고를 생성한다. 교사는 이 초고의 전체적인 완성도와 명료성을 검토한다.
⑧ 교사-AI 반복 협업 정교화: 개발 교사는 최종 초고를 바탕으로 “이 선택지는 매력도가 떨어진다” 또는 “발문의 표현이 모호하다”와 같이 구체적인 피드백을 제공한다. AI는 이 피드백을 반영하여 문항을 수정하며, 이 피드백과 수정의 순환 과정은 문항이 최종적인 완성도를 갖출 때까지 반복된다. <표 3>은 이러한 프로토콜 절차에 대한 개요이다.
특히 6단계 이후부터는 AI가 메타인지 기반 자기 진단을 수행하고, 교사는 이를 기반으로 반복적인 피드백과 수정을 통해 최종 문항을 완성한다(Shah, 2024). 이 구조는 AI가 사고 흐름을 내적으로 구성한 상태에서 교사가 지속적으로 개입함으로써 문항의 설계 오류와 사고 왜곡을 사전에 방지할 수 있도록 한 점에서 기존의 단순 생성·검토 방식과 본질적으로 구별된다(Huang, Zhang & Liu, 2022).
<표 4>는 GAI-HITL 프로토콜의 6단계와 8단계가 실제로 적용된 과정을 보여준다. 개발 교사는 먼저 6단계의 일환으로, AI에게 기출 문제를 참고하여 “개선안을 제시”하라는 메타 인지적 자기 점검 프롬프트를 입력했다. 이 결과를 바탕으로, 8단계 ‘반복 협업 정교화’에서 개발 교사는 “4번 선지가 너무 명확하게 할당관세인 게 보인다”며 난이도 상향을 요구하는 1차 피드백을 제공했다. AI는 이 지적을 수용하며 “정답 선지임을 단서로 추론하기 쉬운 표현들이 많다”고 스스로 분석하고, 수정 방향을 제시했다. 이어서 개발 교사는 “발문에서 ‘두 정책 목표를 모두 고려’하라고 했는데 1번 선지는 하나만 언급해서 오답 판별이 너무 쉽다”는 2차 피드백을 추가로 제공했다. AI는 이 피드백을 반영하여 모든 선지가 두 정책 목표의 긴장 관계를 포함하도록 문항 전체를 재구성하였다. 이처럼 교사의 전문적 판단과 AI의 분석적 제안이 결합되는 구체적이고 반복적인 상호작용을 통해 문항의 완성도를 높여나갔다.



프롬프트 상에서는 AI가 학습자의 인지적 복잡성을 고려하여 각 지문과 성취 기준에 따라 ① 사실적 독해, ② 추론적 독해, ③ 비판적 독해, ④ 창의적 독해의 네 가지 사고 유형을 균등하게 반영하도록 지시되었으며, 총 6개 지문에서 유형별로 4문항씩, 총 24문항이 생성되었다. 프롬프트는 문항 생성자의 역할 설정, 성취기준 연계, 사고 유형 정의 및 예시 제공, 5지선다형 형식 고정 및 해설 포함 등의 조건을 포함하였으며, 교사는 프롬프트 설계와 AI 출력물에 대한 실시간 피드백을 통해 표현 오류나 논리적 결함이 없는 고품질 문항이 생성되도록 지속적으로 개입하였다. 즉, 문항 생성 초기부터 GAI-HITL 프로토콜 8단계 전체에 걸쳐 교사 1인이 개발자로서 함께 참여하였으며, AI의 사고 흐름을 보조하고 문항 구조와 표현을 교육적 기준에 맞게 정교화하였다.
이와 같이 생성된 24개의 초고 문항은 GAI-HITL 프로토콜을 거쳐 구조화되었고, 이후 교사 중심의 2단계 검토 절차를 통해 교육적 완성도를 최종적으로 확보하였다. 이 검토는 동일 학교 소속 교사 3인이 참여한 협의 평가 형태로 이루어졌으며, 다음의 두 가지 하위 과정으로 구성되었다. 먼저 문항 품질 검토에서는 ① 평가 목적 부합 여부, ② 정보 제시의 명료성, ③ 선지 간 변별력, ④ 언어 표현의 적절성 등을 중심으로 오류와 논리적 결함을 점검하고 수정하였으며, 이어 교육적 적합성 검토에서는 ① 지문 특성에 따른 인지 유형의 적합성, ② 교육과정 연계성, ③ 학습자 수준에 맞는 난이도(인지적 부하)를 종합적으로 평가하여 최종 선별을 수행하였다.
이 과정에서 확인된 주요 결과 중 하나는, 생성형 AI가 특히 비판적 이해 영역에서 문항 구성의 타당도를 확보하는 데 어려움을 보인다는 점이었다. 이는 박고운, 최숙기(2025)의 분석과 일치하며, Maity, Deroy & Sarkar(2024), Alfertshofer 외(2024)가 지적한 바와 같이 생성형 AI 기반 문항에서 빈번히 발생하는 문맥 손실과 논리 비일관성 문제의 일환으로 해석할 수 있다. 예를 들어, AI가 생성한 비판적 이해 문항의 다수는 글의 핵심 논지에 대한 타당한 비판보다, 지엽적인 내용이나 표현을 문제 삼거나, 지문에 근거하지 않은 외부 지식을 끌어와 논지를 왜곡하는 오류를 보였다. 이에 검토 교사 3인은 해당 문항들이 교육과정 성취기준(12독서02-03)에서 요구하는 비판적 사고 능력을 타당하게 측정하기 어렵다고 판단하였고, 논의를 통해 질적 완성도가 확보된 문항만을 선별하는 과정에서 자연스럽게 해당 유형의 문항 수가 조정되었다. 이에 따라 초기 계획되었던 사고 수준 간 균형은 지문별 특성과 문항 완성도를 고려하여 부분적으로 조정되었으며, 최종적으로 총 20개 문항이 채택되었다. 각 문항에는 교사의 사전 예측 난이도(상·중·하)가 함께 부여되어 문항 난이도의 분포도 파악할 수 있도록 하였다(<표 5> 참조).
<표 5>는 최종 선정된 20개 문항의 제재 영역, 사고 유형, 교사 예측 난이도를 보여준다. 독해 수준별로는 사실적 독해 문항이 9개로 가장 많았으며, 교사 예측 난이도 기준으로는 ‘상’으로 분류된 문항이 3개(비판적 이해 1, 창의적 이해 2)였다.
본 연구에서는 GAI-HITL 방식으로 생성된 고등학교 독서 문항의 심리측정학적 특성을 검토하기 위해 고전검사이론(CTT)과 문항반응이론(IRT)을 상호보완적으로 적용하였다. 이는 문항의 난이도와 변별도를 다층적으로 해석하여 생성형 AI 기반 문항 개발의 타당성과 실용성을 입체적으로 평가하기 위함이다(Cappelleri, Lundy & Hays, 2014; Hu, Liu & Zhang, 2021).
분석 전략 측면에서, 본 연구는 CTT를 주 분석틀로, IRT를 보조적 분석틀로 설정하였다. 이는 유효 응답자 53명이라는 표본 수의 한계를 고려한 현실적 판단이다. CTT는 문항 난이도와 변별도의 안정적 추정에 요구되는 최소 표본 크기(N≈50)를 비교적 충족하여(Kline, 2005), 분석의 기본적인 신뢰성을 확보할 수 있다. 따라서 본 연구는 개념이 명확하고 적은 표본에서도 안정적인 통계치를 제공하는 CTT의 장점을 우선적으로 활용하였다. 반면, IRT는 문항과 피험자 특성을 분리하여 분석하는 장점이 있지만(Cappelleri, Lundy & Hays, 2014), 안정적인 모수 추정을 위해 본 연구의 표본보다 훨씬 큰 규모를 요구한다. 따라서 IRT 분석은 CTT만으로는 파악하기 어려운 문항 특성을 탐색적으로 살펴보는 데에만 제한적으로 활용되었다.
CTT는 개인의 관찰 점수(X)가 진점수(T)와 측정 오차(E)의 합으로 구성된다는 기본 가정(X = T + E)에 근거하며(Crocker & Algina, 1986), 문항 난이도는 정답자 비율(p-value)로, 변별도는 점이연 상관계수(r) 및 상·하위 집단 정답률 차이(DI)로 산출된다. 이때 상·하위 집단은 검사 총점을 기준으로 상위 27%와 하위 27%의 학생들로 분류하였다(Kelley, 1939).
<표 7>과 같이 IRT 분석에서는 모델 적합도 검정 결과, 1PL 모형이 데이터에 적절히 부합하는 것으로 나타났다(χ2(20) = 18.72, p = .540). 우도비 검정에서도 2PL 모형이 1PL 모형에 비해 통계적으로 유의미한 개선을 보이지 않아, 간명성의 원칙에 따라 1PL 모형을 채택하는 것이 타당하였다. 그럼에도 본 연구에서는 CTT의 변별도 지표와 비교·분석한다는 탐색적 목적을 위해 2PL 모형의 결과를 참고하였다.
| 모델 | Log_Likelihood | AIC | BIC | 우도비 검정 χ2(df) | p-값 |
|---|---|---|---|---|---|
| 1PL | -517.99 | 1075.98 | 1175.30 | 18.72(20) | 0.540 |
| 2PL | -508.63 | 1097.27 | 1295.91 |
그러나 본 연구의 표본 크기(N = 53)는 2PL 모형의 안정적인 모수 추정을 위해 권장되는 최소 수준(일반적으로 약 400∼500명)에 미치지 못하는 명백한 한계를 갖는다(Thorpe & Favia, 2012). 두 모형의 측정 정밀도를 비교하기 위해 피험자 능력 수준(θ)에 따른 측정표준오차(Standard Error of Measurement, SEM)를 분석하였다. 측정표준오차는 검사정보함수(Test Information Function, TIF)의 제곱근에 반비례하므로, 정보량이 많을수록 측정 오차는 작아진다. 본 연구에서 2PL 모형은 θ ≈ –2.0 ~ +3.0 구간에서 1PL 모형보다 일관되게 높은 검사정보량을 제공하였고, 이에 따라 이론적 기대에 부합하게 대부분의 구간에서 더 낮은 SEM 값을 나타냈다. 예를 들어, 평균적인 능력 수준인 θ = 0에서는 1PL 모형의 SEM이 0.66, 2PL 모형은 0.57이었고, θ = –1 구간에서도 각각 0.71과 0.52로 2PL 모형의 정밀도가 더 높았다. 그러나 극단적 능력 구간(예: θ = –4.0)에서는 2PL 모형의 SEM이 1PL보다 약 3배 이상 높게 나타나는 등 일부 구간에서는 이론적 기대와 상반된 결과가 확인되었다. 이는 소표본 상황에서 2PL 모형의 문항 변별도(a) 모수 추정이 불안정해짐에 따라 TIF 자체의 정밀도가 저하되고, 결과적으로 실제 측정오차가 증가했을 가능성을 시사한다(Reise & Waller, 2009; Finch & French, 2019). 따라서 이론적 SEM과 실측된 총 SEM 간의 구분이 필요하며, 특히 소규모 표본 기반 연구에서는 2PL 모형의 정밀도 해석에 신중을 기할 필요가 있다.
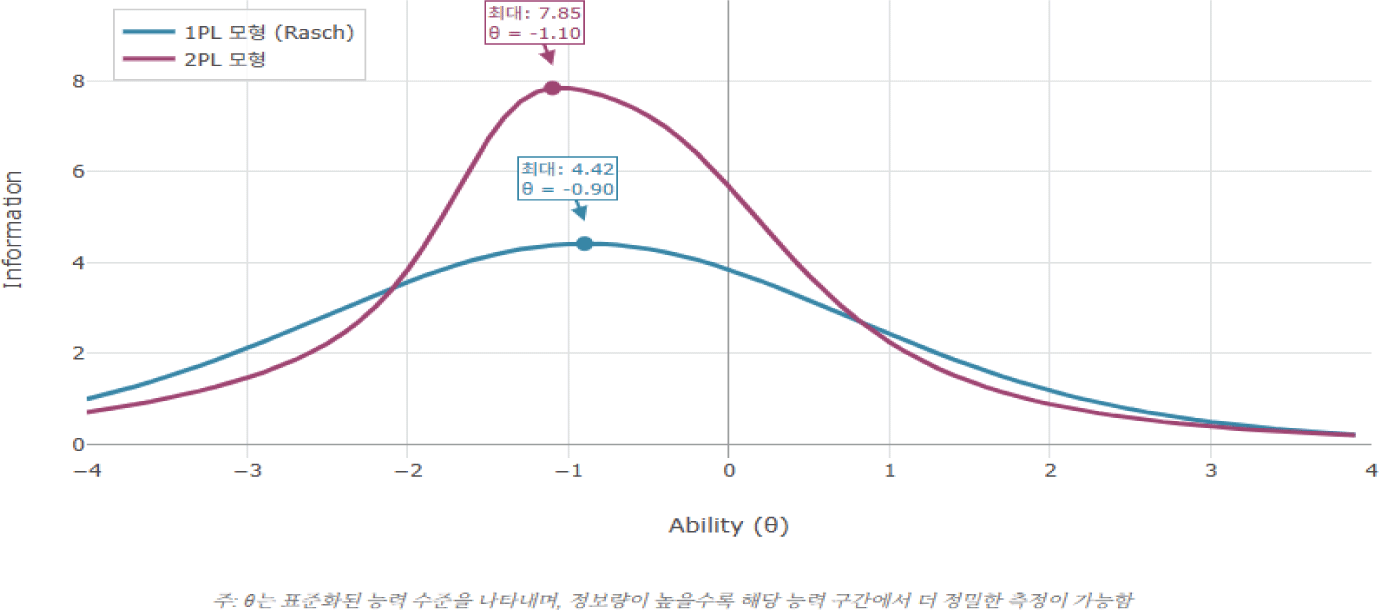
이에 2PL 모형의 분석 결과는 문항 특성에 대한 확정적인 판단의 근거로 활용하기보다, CTT 분석 결과와의 경향성을 비교하는 탐색적 자료로만 제한적으로 참고하였다. 2PL 모형의 변별도(a) 값은 CTT의 변별도 지수와 경향성을 비교하는 참고 자료로만 활용하였으며, 모수 값 자체의 절대적 의미는 신중하게 해석하였다. 문항 해석 기준은 CTT 기반 변별도(DI)의 경우 높은 변별도(D ≥ .40)부터 매우 낮음(D < .20)으로 분류하고(Wu, Tam & Jen, 2016), IRT 기반 변별도(a)는 참고를 위해 매우 높음(a ≥ 2.0)부터 매우 낮음(a < 0.5)으로 구분하였다(Magis, Yan & von Davier, 2017).
본 연구의 모든 통계 분석은 R 소프트웨어(Ver. 4.3.x)를 활용하였으며, CTT 분석에는 CTT 패키지를, IRT 분석에는 ltm 패키지를 사용하였다.
IV. 연구 결과
본 절에서는 GAI-HITL 기반 자동 문항 생성 프로토콜을 통해 개발된 총 20개 문항에 대해 고등학교 3학년 학습자들이 실제로 응답한 결과를 바탕으로 수행한 기초 통계 분석 결과를 제시한다. 이는 후속 심리측정 분석(CTT 및 IRT)에 앞서 문항군 전체의 난이도 분포, 정답률 경향, 내적 일관성 수준 등을 확인하고, GAI-HITL 기반 문항이 학습자 수준에 비추어 교육적으로 적절한 문항 특성을 지니고 있는지를 검토하기 위한 목적을 지닌다. 주요 기초 통계 분석 결과는 <표 8> 및 <표 9>와 같다.
| 최솟값 | 1/4값 | 중앙값 | 평균값 | 3/4 값 | 최댓값 |
|---|---|---|---|---|---|
| 5.00 | 11.00 | 13.00 | 13.36 | 17.00 | 19.00 |
GAI-HITL 기반 자동 문항 생성 프로토콜을 통해 개발된 총 20개 문항에 대해 고등학교 3학년 학습자들이 실제로 응답한 결과를 바탕으로 기초 통계 분석을 실시하였다. <표 8>과 <표 9>에 제시된 바와 같이, 전체 20문항에 대한 검사 총점의 평균은 13.36점, 중앙값은 13.00점, 표준편차는 3.42점으로 나타났다. 사분위수 간 범위(IQR)는 6.00점이었으며, 최솟값은 5점, 최댓값은 19점으로 총 14점의 범위를 보였다. 문항군의 내적 일관성 신뢰도를 검토한 결과, Cronbach’s α 계수는 0.7897로 산출되었다. 이는 Nunnally & Bernstein(1994)이 제시한 심리측정 도구의 신뢰도 기준인 0.70을 상회하는 수치로, GAI-HITL 기반으로 설계된 문항 세트가 평가 도구로서 안정적인 내적 일관성을 확보했음을 보여준다.
본 절에서는 GAI-HITL 기반 자동 문항 생성 프로토콜을 통해 개발된 고등학교 독서 문항 20개에 대해 문항 난이도 분석을 실시하였다. 분석은 고전검사이론(CTT)과 문항반응이론(IRT)을 병행 적용하여, 각각 정답률(p)과 난이도 모수(b)를 추정하고, 교사의 사전 예측 난이도와의 정합성을 비교하는 방식으로 이루어졌다. <표 10>은 문항별 난이도 분석 결과를 정리한 것이다.
<표 11>에 제시된 바와 같이, 전체 문항의 CTT 기반 정답률 평균은 0.6709(SD = 0.1134), IRT 기반 난이도 평균은 –1.0562(SD = 1.0393)로 나타났으며, 이는 전체 문항군이 비교적 쉬운 수준으로 구성되었음을 보여준다. 특히 정답률이 0.70 이상인 문항이 절반 이상을 차지하고, IRT b값이 대부분 음수에 분포함에 따라, 학습자 평균 능력 수준보다 낮은 인지 요구 수준에서 문항이 구성되었음을 알 수 있다.
| 난이도 지표 | 최소값 | 최대값 | 평균 | 표준편차 |
|---|---|---|---|---|
| CTT_p | 0.3962 | 0.8868 | 0.6709 | 0.1134 |
| IRT_b | -3.6451 | 0.641 | -1.0562 | 1.0393 |
교사 예측 난이도와의 정합성은 <표 12>에서 확인할 수 있다. CTT 기준 일치율은 55%, IRT 기준 일치율은 65%로, IRT가 교사의 판단과 더 높은 일치도를 보였다. CTT와 IRT 간의 정합성은 75%로 가장 높았으며, 이는 두 측정 이론이 서로 다른 계산 논리를 가지면서도 실질적으로는 유사한 문항 특성을 측정하고 있음을 보여준다. <표 13>의 상관분석 결과에서도 교사 예측 난이도와 CTT 간에는 중간 정도의 정적 상관관계(Pearson r = .619, p < .01), 교사 예측과 IRT 간에는 유의미한 부적 상관관계(Pearson r = -.598, p < .01; Spearman ρ = -.478, p < .05)가 나타났고, CTT와 IRT 간에는 매우 높은 부적 상관(Pearson r = -.911, p < .01)이 나타났다. [그림 2]의 산점도에서도 이러한 높은 상관관계를 시각적으로 확인할 수 있다. 특히 교사 예측과 IRT 간의 부적 상관은 교사가 더 어렵다고 예측한 문항일수록 IRT에서는 상대적으로 낮은 b값(쉬운 문항)을 보인다는 것을 의미하며, 이는 교사의 직관적 판단과 IRT 모델의 능력 기반 추정 간 체계적 차이를 시사한다. <표 10>의 문항별 분석 결과와 <표 11>의 기술통계 요약을 통해 세부적인 난이도 특성을 살펴보면, CTT와 IRT의 난이도 해석이 일치한 문항은 q1, q5, q11, q16 등 총 15개 문항으로, 양 이론 모두 동일하게 쉬운 또는 어려운 문항으로 판단하였다. 예를 들어, q5는 CTT 정답률이 0.7736, IRT b값이 –3.6451로 매우 쉬운 문항으로 해석되었으며, q16은 정답률 0.3962, b값 0.641로 가장 어려운 문항으로 분석되어, 두 지표가 높은 정합성을 보였다.
| 지표 쌍 | 일치 문항 수 | 일치율 (%) |
|---|---|---|
| 교사 예측 vs CTT_p | 11 | 55% |
| 교사 예측 vs IRT_b | 13 | 65% |
| CTT_p vs IRT_b | 15 | 75% |
| (Pearson Correlation) | 스피어만 상관계수(Spearman Correlation) | |||
| 교사예측난이도 | CTT_p | IRT_b | ||
| 교사예측난이도 | 0.619 | -0.598 | ||
| CTT_p | 0.623 | -0.911 | ||
| IRT_b | -0.478* | -0.786 | ||
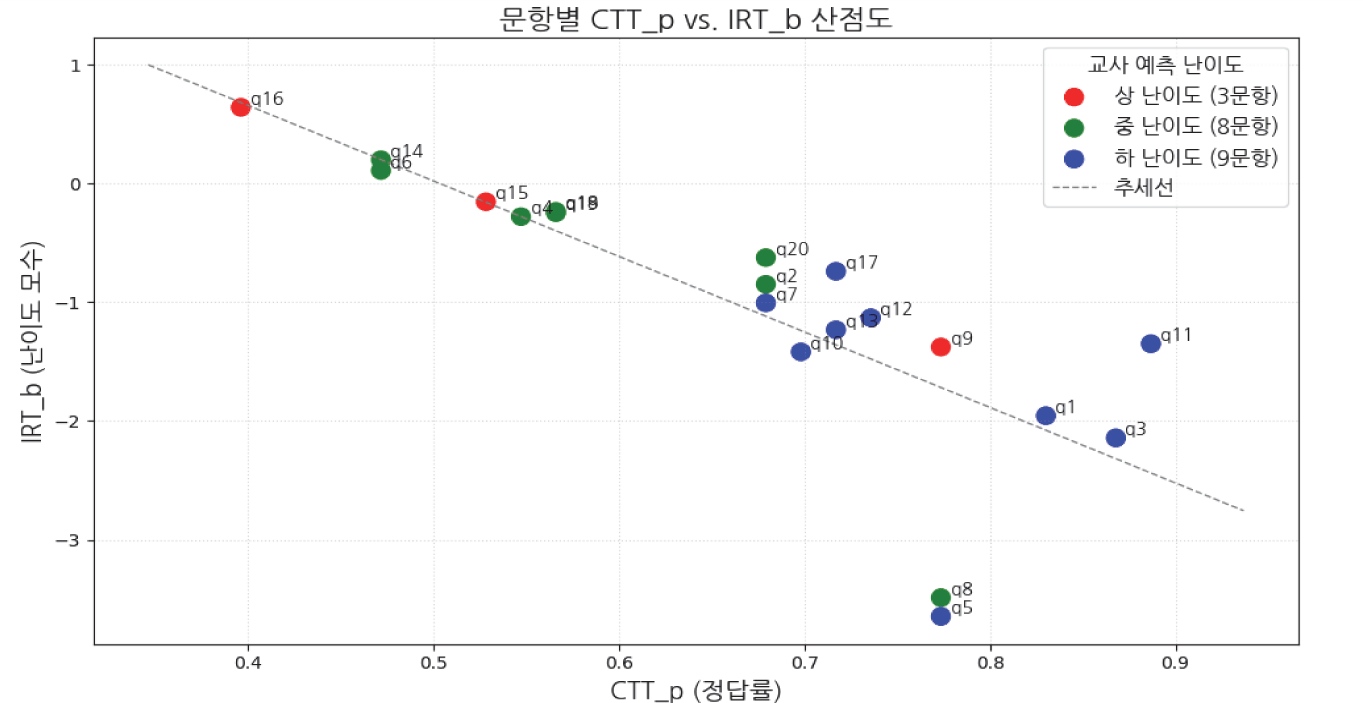
반면 일부 문항은 CTT와 IRT 간 해석이 상이하였다. q2는 CTT 기준으로는 정답률 0.6792로 ‘중간’ 수준이지만, IRT에서는 b값이 –0.8488로 쉬운 문항으로 해석되었다. 이는 CTT의 난이도(p)가 단순히 정답자 비율에 의해 결정되는 것과 달리, IRT의 난이도(b)는 ‘50%의 정답 확률을 갖는 능력 수준’을 의미하기 때문에 나타나는 현상이다(Baker, 2001). 즉, q2 문항의 경우 평균적인 정답률에도 불구하고 상대적으로 낮은 능력 수준의 학생들도 다수 정답을 맞혔기에, IRT 모델은 해당 문항이 높은 능력을 요구하지 않는 ‘쉬운’ 문항이라고 판단한 것이다(Hambleton, Swaminathan & Rogers, 1991). 유사하게 q4도 CTT 정답률은 0.5472로 ‘중간’ 수준이나, IRT b값은 –0.2795로 평균(0)보다 약간 낮은 ‘쉬운 문항’으로 분석되었다. 이 두 지표 간의 불일치는 해당 문항이 가진 인지적 요구의 복잡성에서 기인한 것으로 해석된다. 예를 들어, q4 문항(‘채권의 수익률’ 지문)은 수치를 활용한 추론을 요구하는데, 선택지 중 하나가 매우 매력적인 오답으로 기능하여(1번 선택지 반응률 17.0%) 능력 수준이 중간 이하인 학생들이 오답을 선택할 확률을 높였다. 이처럼 선택지 구조의 미세한 차이가 CTT와 IRT 난이도 추정치 간의 불일치에 영향을 미친 것으로 보인다. 그러나 본 연구의 이러한 추정은 향후 후속 연구를 통해 보다 심화된 질적 분석과 연계하여 논의할 필요가 있다.
<표 14>는 교사의 사전 예측과 실제 결과 간 불일치가 나타난 특이 문항의 분석 사례를 요약한 것이다. 교사가 실제보다 어렵다고 예측한 대표적인 사례는 q8과 q9이다. q8은 ‘중’ 난이도로 분류되었으나 정답률 0.7736, b값 –3.4871로 실제로는 쉬운 문항으로 기능하였으며, q9는 ‘상’ 난이도로 분류되었으나 동일한 정답률과 b값 –1.377로 쉬운 문항으로 나타났다. 두 문항 모두 인문(철학) 영역의 지문에 기반하며, 지문 내 정보가 명시적으로 제공되거나 논리 구조가 선명하여 학습자의 추론 과정이 단순화된 것이 주요 원인으로 보인다. 반대로 교사가 쉽게 예측한 문항 중 실제로는 어려웠던 사례로는 q6과 q14가 있다. q6은 창의적 이해 문항으로, 정답률 0.4717, b값 0.1086으로 어려운 문항으로 작용하였다. 선택지 간 반응 분산이 크고, 정답 응답이 확연히 집중되지 않아 학습자들이 정답을 명확히 구별하기 어려웠던 것으로 해석된다. q14는 추론적 이해를 요구하는 사회영역 문항으로, 수치적 개념 혼동이나 매력적인 오답의 존재가 학습자의 판단을 어렵게 만든 것으로 분석된다. 반면, 교사의 예측과 실제 결과가 일치한 대표 문항으로는 q1과 q16이 있으며, 이는 명시적 단서의 제공 여부, 고차적 사고 요구의 명확성 등과 연관되어 있음이 확인되었다.
본 절에서는 GAI-HITL 기반 자동 문항 생성 프로토콜을 통해 개발된 고등학교 독서 문항 20개에 대해 변별도 분석을 실시하였다. 분석은 고전검사이론(CTT)의 점이연상관계수(r) 및 상하위집단 변별도(DI), 문항반응이론(IRT)의 변별도 모수(a)를 중심으로 이루어졌으며, 각 지표 간의 기술통계적 특성과 정합성, 그리고 문항별 특이 사례에 대한 해석을 통해 자동 생성 문항의 판별력 수준을 종합적으로 평가하고자 하였다. 문항별 상세 변별도 지표는 <표 15>에 제시하였다.
| 변별도 수준별 문항 분포 요약 | |||
|---|---|---|---|
| 구분 | 양호 | 보통 | 미흡 |
| CTT_r | 11 (55%) | 5 (25%) | 4 (20%) |
| DI | 13 (65%) | 5 (25%) | 2 (10%) |
| IRT a | 10 (50%) | 7 (35%) | 3 (15%) |
<표 15>를 바탕으로 문항별 특성을 살펴보면, 먼저 변별도가 우수한 문항들의 경우, q18(CTT_r = 0.541, IRT_a = 2.2035)과 q19(CTT_r = 0.486, IRT_a = 1.785), 그리고 q6(CTT_r = 0.405, IRT_a = 1.2847) 등이 대표적이다. <표 18>에서 확인할 수 있듯, 이들 문항은 정답률이 40~60% 구간에 분포하며 오답 선택지에 응답이 고르게 분산되는 이상적인 패턴을 보였다. 이는 정답률 중간 수준에서 변별력이 극대화된다는 Popham(2017)과 Haladyna(2004)의 이론을 실증적으로 뒷받침한다. 반면, q5(CTT_r = 0.1484)와 q8(CTT_r = 0.1600)은 매우 낮은 변별력을 나타냈다. 두 문항 모두 정답 선택지에 응답자가 과도하게 집중되었고(정답률 77.4%), 특히 q8은 하나의 오답 선택지에 아무도 응답하지 않아 오답의 기능성이 결여된 문제를 보였다(Haladyna & Rodriguez, 2013). 예외적으로 q11은 정답률이 88.7%로 매우 쉬웠음에도, CTT_r = 0.473, IRT_a = 3.311이라는 매우 높은 변별력을 기록하여, 매력적인 오답이 소수 학생들을 효과적으로 변별해 낸 특이 사례로 분석되었다. <표 15>의 결과를 종합한 전체 문항의 변별도 기술통계는 <표 16>과 같다. CTT 기반의 점이연 상관계수(r)는 평균 0.3563, DI는 평균 0.5061, IRT의 변별도 모수(a)는 평균 1.1992로, 대부분의 문항이 중간 이상 수준의 변별력을 갖추고 있음을 시사한다.
| 지표 | 최소값 | 최대값 | 평균 | 표준편차 |
|---|---|---|---|---|
| CTT_r | 0.1484 | 0.5406 | 0.3563 | 0.0914 |
| DI | 0.2143 | 0.7857 | 0.5061 | 0.173 |
| IRT a | 0.3452 | 3.3111 | 1.1992 | 0.7623 |
문항별로 살펴보면, q18은 정답률 56.6%, CTT_r = 0.541, IRT_a = 2.2035로 모든 지표에서 뛰어난 변별도를 보였다. 정답 외 선택지에도 고르게 분산된 응답 패턴을 보여 학습자의 능력 수준 차이를 민감하게 포착한 문항이다. 유사하게 q19는 정답률 56.6%, CTT_r = 0.486, IRT_a = 1.785로 높은 변별력을 보였으며, 선택지 간 분산이 이상적으로 이루어졌다. q6 또한 정답률 47.2%, CTT_r = 0.405, IRT_a = 1.2847로 우수한 변별력을 보였고, 창의적 이해 유형이라는 점에서 인지적 복잡성이 적절히 작용한 것으로 해석된다. 이들 문항은 정답률이 40~60% 구간에 분포하며, 선택지 간 반응 분산이 잘 이루어져 이상적인 문항 반응 패턴을 형성한 사례이다. 특히 q18과 q19는 선택지별 응답이 균형 있게 분산되면서 학습자의 능력에 따른 정답 도달 양상이 명확히 구분되었으며, 이는 정답률 중간 수준에서 변별력이 극대화된다는 Popham(2017)과 Haladyna(2004)의 이론을 실증적으로 뒷받침한다.
반면, q5는 정답률 77.4%, CTT_r = 0.1484, IRT_a = 0.3452로, q8은 정답률 77.4%, CTT_r = 0.1600, IRT_a = 0.3617로 매우 낮은 변별력을 나타냈다. 두 문항 모두 정답 선택지에 응답자가 과도하게 집중되었고, 특히 q8은 5번 선택지에 아무도 응답하지 않아 실질적으로 4지선다 문항으로 작동하였다. 이는 Haladyna & Rodriguez(2013)가 지적한 오답 선택지의 기능성 결여 문제를 그대로 드러낸 사례이며, 선택지 설계상의 미흡함이 문항의 구분 능력을 심각하게 저해함을 보여준다. Tarrant, Ware & Mohammed(2009)의 연구에서도 언급된 바와 같이, 선택지 간 응답의 불균형은 문항의 타당성과 기능성을 심각하게 약화시키며, q5, q8의 사례는 이를 그대로 입증한다. 예외적으로 q11은 정답률 88.7%로 매우 높은 정답 집중도를 보였음에도 불구하고, CTT_r = 0.473, IRT_a = 3.311이라는 매우 높은 변별력을 기록하였다. 이는 대부분의 응답자가 정답을 맞혔지만, 일부 오답 선택지가 제한된 수의 학습자에게 혼란을 유발할 수 있는 매력적 오답으로 기능했을 가능성을 보여준다. 오답 선택지의 기능성이 완전히 상실되지 않았고, 정답을 선택한 학습자들의 사고 경로가 보다 일관되었다는 점에서, 문항의 논리 구조가 명확하면서도 교육적 설계가 성공적으로 구현된 사례로 해석할 수 있다. 그러나 이는 단일 문항의 특이 현상으로 일반화에는 주의가 필요하다.
<표 18>에 제시된 정답률 집중도별 분류에 따르면, 60∼75% 구간에 위치한 문항들(q20, q17, q2, q12, q13 등)은 CTT_r = 0.350.48, IRT_a =1.0∼2.1로 안정적인 변별력을 보였다. 예를 들어 q20은 정답률 67.3%, CTT_r = 0.4857, IRT_a = 2.085로 변별력이 우수하였으며, 선택지 반응 분산도 적절히 분포되었다. 반면 q1, q3, q4와 같은 문항들은 정답률은 높지만, CTT_r이 0.30 내외로 상대적으로 낮은 변별도를 보였고, 선택지 분산도 불균형한 편이었다. 이들 문항은 매력적인 오답 구성의 결여로 인해 응답자의 실제 능력 차이를 충분히 드러내지 못한 사례로 해석되며, 난이도 조정이나 선택지 개선이 필요한 문항으로 분류된다.
변별도 지표 간 정합성을 분석한 결과(<표 17> 참조), CTT_r과 DI 간 Pearson 상관계수는 0.883, Spearman 상관계수는 0.809로 매우 높은 수준의 일치도를 보였으며, 이는 두 CTT 기반 지표가 측정 대상의 동일성과 정합성을 입증한다. 반면 CTT_r과 IRT_a 간 상관은 Pearson r = 0.681, DI와 IRT_a 간 상관은 r = 0.574로 중간 수준의 수렴 타당성을 보여주었다. 이는 CTT가 전통적 응답 데이터를 기반으로 하고, IRT는 능력 수준에 따른 확률 모델에 기반한다는 이론적 차이에서 기인하며, 서로 다른 방식으로 변별력을 측정하면서도 문항의 기능성에 대한 판단은 일정 부분 일치하고 있음을 보여준다. 특히 Spearman 상관계수가 전반적으로 Pearson 상관계수보다 높게 나타난 점은 변별력 지표 간의 순위 기반 해석에서 높은 일관성을 의미하며, 문항 선별이나 개선 우선순위 설정 시 실질적 활용 가능성을 시사한다.
| (Pearson Correlation) | 스피어만 상관계수(Spearman Correlation) | |||
| CTT_DI | CTT_r | IRT_a | ||
| CTT_DI | 0.809 | 0.557* | ||
| CTT_r | 0.883 | 0.574* | ||
| IRT_a | 0.681 | 0.687 | ||
이러한 분석 결과는 본 검사가 측정하고자 하는 구인, 즉 ‘독해 능력’에 대한 구인 타당도(construct validity)를 지지하는 하나의 증거로 고려될 수 있다. Messick(1989)에 따르면, 구인 타당도에 대한 주장은 다양한 증거를 통해 종합적으로 뒷받침되어야 하며, 그 증거의 원천 중 하나로 검사의 내적 구조(internal structure)가 언급된다. 본 검사는 선행 연구 및 교육과정 분석을 통해 ‘독해 능력’의 핵심 요소를 반영하여 개발되었으므로, 검사 총점은 학생의 독해 능력을 나타내는 타당한 대리 변인(proxy variable)으로 간주할 수 있다. 이러한 맥락에서 문항 변별도는 검사의 내적 구조 일관성을 살펴볼 수 있는 유용한 지표 중 하나이다. 특정 문항의 변별도가 높게 나타났다는 것은, 검사 총점으로 대변되는 잠재 능력 수준이 높은 학생과 낮은 학생을 해당 문항이 비교적 성공적으로 구별해 낼 가능성을 시사한다. 이는 개별 문항이 전체 검사와 유사한 구인, 즉 ‘독해 능력’을 일관되게 측정하고 있을 개연성을 뒷받침하는 결과로 해석될 수 있다(Allen & Yen, 1979).
이러한 관점에서 <표 18>의 결과를 살펴보면, 정답률 40∼60% 구간에 위치한 q6, q18, q19, q15는 CTT 변별도 기준으로 0.37 이상을 기록하여 상대적으로 우수한 변별력을 보이는 것으로 나타났다. 또한, 정답 외 선택지들에도 응답이 고르게 분산된 경향은 효과적인 오답이 기능하고 있음을 보여주며(Haladyna, 2004), 해당 문항들이 능력 수준이 다른 학습자들을 변별하는 데 긍정적으로 기여하고 있음을 시사한다.
본 연구의 의의를 명확히 하기 위해, 변별도 분석 결과를 GAI-HITL 프로토콜과 연계하여 심층적으로 분석하면 다음과 같다.
첫째, 우수 변별도 문항(q18, q19)의 성공 요인은 ‘교사-AI 반복 협업 정교화(8단계)’ 과정에서 찾을 수 있다. 예를 들어, 가장 높은 변별도(CTT_r=0.541,IRT_a=2.2035)를 보인 q18(‘임대차 계약’ 지문)의 경우, AI가 생성한 초고의 오답 선택지들은 단순히 ‘틀린’ 내용으로 구성되어 매력도가 낮았다. 그러나 개발 교사가 8단계에서 “정답과 유사한 논리 구조를 갖지만 결정적인 오류를 포함하는 매력적인 오답으로 수정해달라” 구체적인 피드백을 제공했고, AI는 이 피드백을 반영하여 법률 용어와 조건을 미묘하게 변경한 오답들을 생성했다. 이처럼 교사의 전문적 판단에 기반한 정교한 피드백이 AI의 생성 능력을 특정 방향으로 유도함으로써, 결과적으로 학습자의 고차원적 사고 능력을 변별하는 데 성공적인 문항이 개발될 수 있었다.
둘째, 낮은 변별도 문항(q5, q8)의 원인은 ‘자기 점검 및 오류 탐지(6단계)’의 한계와 관련이 깊다. 변별도가 매우 낮았던 q5(‘관세’ 지문)의 경우, AI는 6단계 자기 점검에서 “논리적 오류 없음” 로 자체 진단했다. 개발 교사 역시 8단계 검토 과정에서 해당 문항의 오답 선택지가 가진 문제점(지나치게 정답과 거리가 멂)을 간과하고 다른 문항에 피드백을 집중했다. 이는 AI의 메타인지적 자기 점검이 완벽하지 않으며, 이를 보완해야 할 교사의 개입(HITL)이 충분히 이루어지지 않았을 때 문항의 질적 저하가 발생할 수 있음을 명확히 보여주는 사례이다.
이처럼 GAI-HITL 기반 문항의 심리측정학적 특성은 단순히 문항 자체의 내적 속성만으로 결정되는 것이 아니라, 생성 프로토콜의 각 단계에서 이루어지는 교사와 AI의 상호작용 방식과 질에 직접적인 영향을 받는다. 따라서 본 연구의 난이도 및 변별도 분석 결과는 GAI-HITL이라는 개발 방식의 가능성과 한계를 동시에 보여주는 구체적인 증거라 할 수 있다.
V. 결론 및 제언
본 연구는 생성형 인공지능과 교사 전문성의 협업을 구조화한 GAI-HITL(Generative AI–Human-in-the-Loop) 기반 자동 문항 생성 방식이 고등학교 국어과 독서 평가에서 심리측정학적 타당성과 교육적 실효성을 확보할 수 있는가를 실증적으로 검토하였다. 총 53명의 고등학교 3학년 학습자의 응답을 바탕으로 고전검사이론(CTT), 문항반응이론(IRT), 변별도 지표 등을 통합적으로 분석함으로써, 자동 생성된 독서 문항의 난이도, 변별도, 신뢰도 등 주요 심리측정 특성에 대한 다면적 검토를 수행하였다.
연구의 결과를 요약하면 다음과 같다.
첫째, GAI-HITL 기반 문항 세트는 평가 도구로서 요구되는 기본적인 양호도를 확보하였다. 구체적으로, 전체 문항의 평균 정답률은 66.8%로 학습자 집단에 적절한 난이도로 기능했으며, 점수 분포 역시 특정 수준에 편중되지 않고 고른 변별 가능성을 보였다. 또한, 내적 일관성 신뢰도(Cronbach’s α = .7897)는 교육평가에서 요구하는 기준을 상회하여, 개발된 문항들이 측정하고자 하는 구인을 일관되게 측정하고 있음을 뒷받침했다.
둘째, 난이도 분석 결과, 문항 대부분이 학습자 평균 능력보다 약간 쉬운 수준에 분포하였으며, 교사 예측 난이도와의 정합성은 CTT 기준 55%, IRT 기준 65%로 비교적 높은 수준을 보였다. 다만 문항별로는 사고 수준, 지문 구조, 선택지 유사성 등 다양한 요인이 실제 난이도에 영향을 주었으며, 단순한 제재 영역 분류나 직관적 판단만으로 문항 난이도를 예측하는 데 한계가 있음을 보여주었다.
셋째, 변별도 분석 결과, 다수의 문항이 양호한 변별력을 갖춘 것으로 나타났다. CTT 점이연상관(r) 기준 55%, 상하위집단 변별도(DI) 기준 65%, IRT 변별도 모수(a) 기준 50%의 문항이 양호 이상 수준으로 분석되었다. 특히 정답률이 40~60% 구간에 위치한 문항들(q6, q18, q19 등)은 오답 선택지 간 응답 분산이 고르게 이루어져 매우 우수한 변별력을 보였으며 이는 Haladyna(2004)와 Messick(1989)의 문항 설계 원칙을 실증적으로 뒷받침하는 결과이다.
넷째, 지표 간 정합성 분석에서는 CTT_r과 DI 간 Pearson r = 0.883, CTT_r과 IRT a 간 r = 0.681로 높은 수렴 타당성이 확인되었고, 스피어만 상관계수가 더 높게 나타나 실용적 평가 상황에서 지표 간 순위 일치도가 높음을 시사하였다. 이는 서로 다른 분석 이론 간에도 자동 생성 문항의 판별력이 일관된 방향으로 평가됨을 의미한다.
다섯째, 가장 핵심적인 발견으로, 생성 문항의 심리측정학적 품질이 GAI-HITL 프로토콜 내 교사와 AI의 상호작용 방식 및 질과 직접적으로 연관됨을 확인했다. 우수한 변별도를 보인 문항(q18 등)은 ‘8단계: 반복 협업 정교화’에서 교사의 구체적인 피드백을 통해 오답의 매력도가 향상된 성공 사례였던 반면, 변별력이 낮았던 문항(q5 등)은 ‘6단계: 자기 점검’에서 AI와 교사 모두 문제점을 간과한 사례로 분석되었다. 이는 GAI-HITL 방식의 성공이 단순히 기술을 사용하는 것을 넘어, 인간 전문가의 시의적절하고 정교한 개입에 좌우됨을 시사한다.
이상의 결과는 GAI-HITL 방식의 자동 문항 생성이 현재의 기술 수준에서도 실용 가능한 평가 도구를 생산할 수 있는 가능성을 보여주는 실증적 근거로 해석할 수 있다. 특히 GIA의 출력물을 교사의 판단과 구조화된 검토 절차를 통해 정교화함으로써 교육 현장에 적용 가능한 신뢰도 높은 평가 도구를 개발할 수 있음을 확인하였다.
후속 연구의 제언 사항을 제시하면 다음과 같다. 본 연구의 탐색적 결과를 바탕으로 GAI-HITL 기반 국어과 독서 문항 개발의 실용화를 위한 단계적 발전 방안을 다음과 같이 제안한다.
첫째, 선택지 품질 관리 체계의 내재화가 최우선 과제이다. 본 연구에서 확인된 바와 같이, 오답 선택지의 기능성 결여는 문항 변별력 저하의 직접적 원인으로 작용하며, 이는 본 연구에서 분석한 바와 같이 교사의 개입이 미치지 못한 부분에서 두드러지게 나타났다. Haladyna(2004)와 Messick(1989)이 강조한 바와 같이 선택지의 질적 수준이 문항의 구인 타당도를 결정하는 핵심 요소임을 고려할 때, 단기적으로는 정답 집중도와 선택지 분산 패턴을 자동 진단하는 품질 관리 도구의 개발이 필요하며, 중장기적으로는 선택지 매력도 예측 알고리즘의 도입을 통해 문항 생성 초기 단계부터 체계적 품질 관리가 이루어져야 한다(Rodriguez, 2005).
둘째, 국어 교사의 문항 개발 역량 강화를 위한 체계적 연수 프로그램이 핵심 전략이다. 소수 교사 참여로 인한 본 연구의 한계를 극복하기 위해, 다양한 배경의 교사들이 GAI-HITL 방식을 효과적으로 활용할 수 있도록 하는 전문성 강화가 필수적이다. 특히 사고 수준별 문항 구성, CoT 기반 프롬프팅 기법, 선택지 기능성 진단 등의 실습 중심 역량 훈련이 필요하며, 교사 학습공동체를 통한 사례 공유와 검토 워크숍이 병행되어야 한다(Kasneci et al., 2023; U.S. Department of Education, 2023). 이는 AI 시대 교육에서 인간 교사의 전문성이 기술과 협력하는 새로운 형태로 진화해야 한다는 관점과 일치한다.
셋째, 후속 연구에서는 보다 다양한 학교급(중학교, 초등학교 포함), 학년 수준, 제재 영역, 사고 수준, 문항 유형(객관식 외 단답형, 서술형 등), 평가 맥락(형성평가, 총괄평가, 진단평가 등)을 아우르는 확장적 설계가 필요하다. 특히 표집 수가 53명에 불과했던 본 연구의 한계를 극복하기 위해 대규모 학습자 데이터를 기반으로 한 CTT 및 IRT 모수 안정화, 문항군별 반응 패턴 군집 분석 등의 후속 실증 연구가 요구된다. 이러한 확장적 접근을 통해 GAI-HITL 방식의 일반화 가능성과 안정성을 보다 체계적으로 검증할 수 있을 것이다.
넷째, 국어과 독서 영역 내 제재별 차별화된 문항 개발 가이드라인 정립이 요구된다. 본 연구에서 사회 영역 독서 문항의 우수한 변별력과 인문 영역에서의 교사 난이도 과대평가 현상이 확인된 만큼, 제재별 특성을 반영한 정교한 접근이 필요하다. Baker(2001)가 제시한 문항 특성과 피험자 능력의 상호작용을 고려할 때, 제재별 문항 설계 원칙과 교사 예측 보정 방안을 포함한 실무 가이드라인을 개발하고 이를 교사 연수 프로그램에 체계적으로 반영해야 한다(Ebel & Frisbie, 1991; Popham, 2017).
다섯째, 장기적으로는 학습자 맞춤형 독서 평가 시스템으로의 발전을 지향하되, 현실적 접근이 필요하다. 현재의 제한적 연구 결과를 고려할 때, Deep Knowledge Tracing과 같은 고도화된 기술의 도입은 충분한 후속 연구와 기술적 검증을 거친 신중한 접근이 요구된다. 우선은 현재 기술 수준에서 구현 가능한 문항 품질 분석 도구의 안정화에 집중하고, Nunnally & Bernstein(1994)이 강조한 점진적 타당화 과정에 따라 시스템을 단계적으로 고도화해 나가는 것이 현실적 대안이다(Hambleton & Swaminathan, 1985; Pandey & Karypis, 2019; Piech et al., 2015).
이와 같은 단계적 발전을 통해 GAI-HITL 방식은 국어과 독서 교육에서 공정하고 신뢰도 높은 평가 도구로 정착될 수 있을 것이며, AI 시대의 교육 혁신과 학습자 중심 평가 체제 구축에 핵심적인 역할을 수행할 수 있을 것이다. 생성형 AI와 교사의 협업이 갖는 시너지 효과는 단순한 자동화의 효율성을 넘어, 교육 전문성과 기술 융합의 새로운 평가 생태계를 구현하는 기반이 될 수 있다. 본 연구는 그 실현 가능성을 실증적으로 제시했다는 점에서 교육 현장과 정책 차원 모두에 유의미한 시사점을 제공한다.